Utilizing Nebula NLP to Derive Data Intelligence
Wednesday, May 26, 2021 by Anthony DeJohn
Nebula comes loaded with many powerful information retrieval features that aid attorneys and investigators in the hunt for key evidence. One of its newer features - Nebula NLP (Natural Language Processing) – brings AI-driven classification with a powerful visual layer to maximize these capabilities. Nebula NLP is a separate feature-set from our industry-leading Predictive Coding technology and brings a complimentary flavor of unsupervised learning to an already robust AI/ML toolkit.
Nebula NLP currently offers two primary tools:
- Entity recognition (extraction, classification, clustering)
- Sentiment analysis
Both of these tools offer insight into unfamiliar data sets and can make a world of difference for many different use cases. Nebula NLP is even available in the Cull module for an enhanced ECA experience.
Entity Recognition, Classification, Clustering
Entity recognition extracts words and phrases that identify people, places, events (etc.) from unstructured data. This is much more than a simple detection of known words in a dictionary. By utilizing pre-trained AI language models, Nebula NLP can find occurrences of words and phrases that identify things (entities) present in a data set. Because this technology works best on authored content, Nebula comes pre-configured to only analyze rich documents like email, Office, and similar filetypes.
Consider the following two examples:
Text Query: “Austin” AND (“Texas” OR “BBQ” OR “Music”)
NLP (locations): “Austin”
Perhaps the results of these two queries will be similar, given that we supplemented our text query to increase the likelihood our search hits will refer to Austin, Texas. But also consider that someone named “Austin” who lives in Kansas City might be a BBQ aficionado. To help avoid these false-positives, we can run the NLP query and rely on AI to help us find documents referencing the Austin we care about.
Using NLP as a deliberate query tool is helpful, but what if you don’t know what you are looking for? In the below example, I used the Nebula NLP visual clustering tool to drill-down on documents referencing the Olympics. What I’d like to do now is determine which news outlets were most prolific covering this event, but I’m not sure where to start. Looking at the “Organizations” category, I can see that most of these bubbles are indeed newspapers and television networks. I am now able to select the bubbles I want, to dynamically create a new query and filter down further on my data.
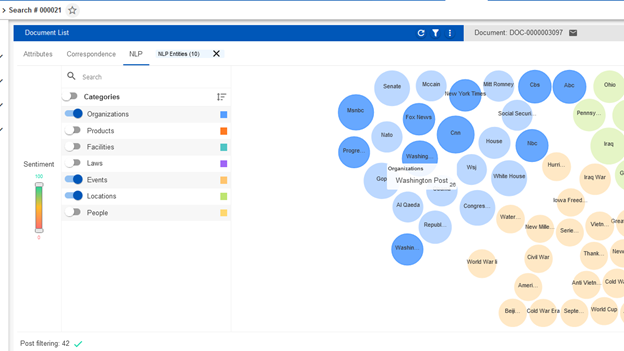
After running this subsequent search, I’m left with only 42 documents. I can now see the entities – in this case the people and locations – contained within those 42 documents (see image below). From here, I have a very good understanding of who/where are the key entities within the data subset that interests me.

Sentiment Analysis
Sentiment analysis in Nebula NLP measures the “tone” of authored content and ranks it within a range of “definitely negative” to “definitely positive.” As with entity recognition, this technology works best on well-suited data. In the case of sentiment analysis, Nebula comes pre-configured to only analyze emails/ – and only the top-most email in a thread. This allows users to focus only on the content that the record is representative of. In special situations where other document types are suitable for sentiment analysis, Nebula does support inclusion of those as well (such as Yelp reviews or news editorials).
Determining doc-level rankings for many lines of text is no easy task, but Nebula NLP simplifies it as much as possible with a unique ranking system. First, Nebula analyzes the top-most email text (headers excluded) one sentence/line at a time. Next, Nebula sends back rankings for the highest (most positive) and lowest (most negative) sentences found within that text. The scores for these sentences are combined into a single searchable field for simplicity. Using the sentiment analysis slider in the NLP filters tab, users can set a high/low threshold for documents.
In the below example, I am interested to find largely neutral documents – those containing no definitely negative or positive sentences. To accomplish this, I’ll set the sliders between 25 and 75 as a starting point and see what comes back.

Note that I can also inverse this logic using the search builder if I’d rather read through documents with more definitive sentiment.
Closing Thoughts
Nebula NLP is a powerful feature that generates actionable data intelligence with very little effort. There are situations where it can move a legal team from a complete standstill to a deep investigation in a matter of minutes. Always be aware of “junk-in, junk-out” – the cleaner the data, the better the results will be. Users should not be afraid to experiment and combine it with other strategies to find crucial information.
There are many other exciting new enhancements coming to Nebula soon. New features for Nebula NLP and entirely new AI/ML solutions are currently undergoing active development in our labs, along with dozens of other feature additions to the core platform.

Anthony DeJohn
Anthony leads KLDiscovery's product and data science initiatives and is the senior product owner for Nebula. He has a passion for finding new ways to solve old & emerging problems by bringing bleeding-edge tech to traditional business verticals. On weekends you'll find him chasing his sons and trying to squeeze in a hockey game while bouncing between DIY construction projects.